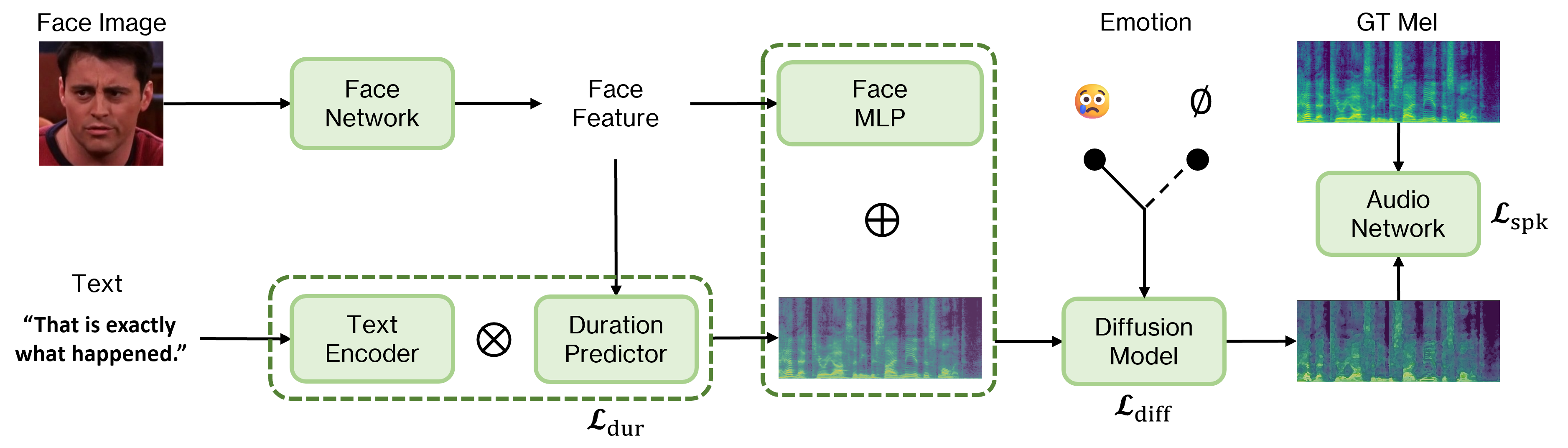
We propose FEIM-TTS, an innovative zero-shot text-to-speech (TTS) model that synthesizes emotionally expressive speech, aligned with facial images and modulated by emotion intensity. Leveraging deep learning, FEIM-TTS transcends traditional TTS systems by interpreting facial cues and adjusting to emotional nuances without dependence on labeled datasets. To address sparse audio-visual-emotional data, the model is trained using LRS3, CREMA-D, and MELD datasets, demonstrating its adaptability. FEIM-TTS's unique capability to produce high-quality, speaker-agnostic speech makes it suitable for creating adaptable voices for virtual characters. Moreover, FEIM-TTS significantly enhances accessibility for individuals with visual impairments or those who have trouble seeing. By integrating emotional nuances into TTS, our model enables dynamic and engaging auditory experiences for webcomics, allowing visually impaired users to enjoy these narratives more fully. Comprehensive evaluation evidences its proficiency in modulating emotion and intensity, advancing emotional speech synthesis and accessibility.
All of the results were using only unseen speakers including synthesized images.

Text: I think I've seen this before.
From Face-TTS
From FEIM-TTS (Ours)

Text: These take the shape of a long round arch, with its path high above,
and its two ends apparently beyond the horizon.
From Face-TTS
From FEIM-TTS (Ours)

Text: Yet the public opinion of the whole body seems to have checked dissipation.
| 1 | 10 | 20 | |
|---|---|---|---|
| Anger | |||
| Disgust | |||
| Fear | |||
| Happy | |||
| Neutral | |||
| Sad |


Text: Maybe tomorrow it will be cold.
Judy Hopps
Kristoff Bjorgman